



Can AI automate computational reproducibility?
A new benchmark to measure the impact of AI on improving science


Last month, Sakana AI released an "AI scientist", which the company called "the first comprehensive system for fully automatic scientific discovery". It was touted as being able to accelerate science without suffering from human limitations.
Unfortunately, the "AI Scientist" has many shortcomings. It has no checks for novelty, so generated papers could rehash earlier work. And Sakana did not perform any human review (let alone expert “peer” review) of the generated papers—so it is unclear if the papers are any good (apparently they are not). While these flaws are particularly flagrant in Sakana's case, the lack of good evaluation affects most AI agents, making it hard to measure their real-world impact.
Today, we introduce a new benchmark for measuring how well AI can reproduce existing computational research. We also share how this project has changed our thinking about “general intelligence” and the potential economic impact of AI. Read the paper.
CORE-Bench: A new benchmark for evaluating AI for reproducing research
Visions of AI automating science are enticing, but aren’t within reach, and lead to flawed science. In contrast, using AI for well-scoped tasks such as verifying computational reproducibility can save a lot of time and redirect effort towards more productive scientific activity. AI could also help find relevant literature, write code to rapidly test ideas, and perform other computational tasks.
In a new paper, we introduce CORE-Bench (Computational Reproducibility Agent Benchmark), a benchmark for measuring how well AI can automate computational reproducibility, that is, reproducing a paper’s findings when the code and data are available. The authors are Zachary S. Siegel, Sayash Kapoor, Nitya Nadgir, Benedikt Stroebl, and Arvind Narayanan. CORE-Bench is a first step in a larger project to rigorously evaluate progress in automating research tasks of increasing difficulty.
Computationally reproducing a study is a far more limited task than replication, which requires re-running experiments that might involve human subjects. Even the limited reproducibility task is hard: In the 2022 Machine Learning Reproducibility Challenge, over a third of the papers could not be reproduced even when experts reproducing the papers had the code and data.

If AI could automate this mundane yet important task, researchers could automate the implementation of baselines, reviewers could more easily assess if a paper has flaws, and journals and conferences could more easily verify if submitted and published papers are reproducible.
We created CORE-Bench using scientific papers and their accompanying code and data repositories. We used Code Ocean to source papers that were likely to be reproducible. We manually reproduced 90 papers from computer science, medicine, and social science, and curated a set of questions for each paper to be able to verify the answers.
We release CORE-Bench with three difficulty levels. Tasks in all three levels require the use of both language and vision capabilities. The hardest version closely resembles real-world reproduction attempts, and we expect that improvements on the benchmark will translate to agents that are actually useful to scientists.
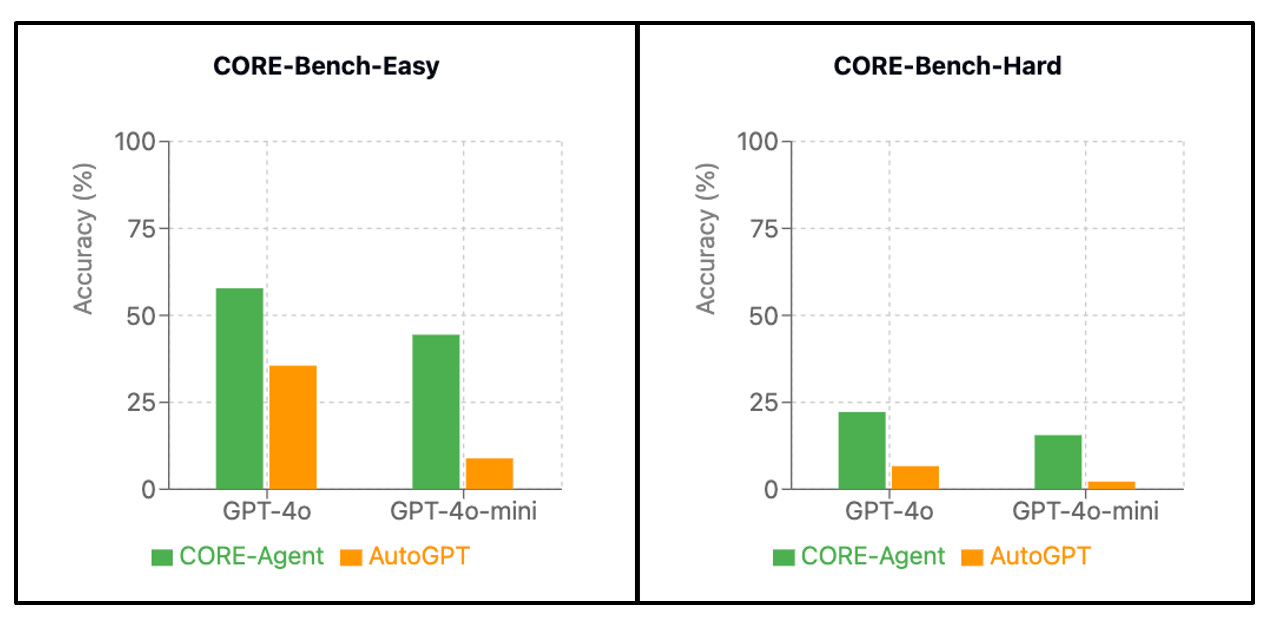
To implement baselines, we tested the generalist AutoGPT agent and also implemented a task-specific modification to AutoGPT, which we call CORE-Agent. While the task-specific version improved accuracy significantly, there is still massive room for improvement: the best agent (CORE-Agent with GPT-4o) has an accuracy of 22% on CORE-Bench-Hard.
Rethinking generality
Computational reproducibility requires setting up the code environment correctly, running the code, and seeing if it produces the same results as reported in the paper. Using the shell and other tools correctly is still tricky for LLMs. When we evaluated generalist agents like AutoGPT, we weren't surprised by their poor accuracy (less than 10% on CORE-Bench-Hard).
Yet, with a few person-days of effort, we were able to build CORE-Agent by modifying AutoGPT, which more than doubled accuracy on the hardest level. We also built a task-specific agent from scratch, but modifying AutoGPT was far less time consuming while also resulting in a stronger agent. We are cautiously optimistic that this approach can be pushed to yield agents that perform well enough to be useful in practice.
If this pattern of being able to easily adapt a generalist agent to produce a task-specific agent holds in other areas, it should make us rethink generality. Generality roughly translates to being able to use the same model or agent without modification to perform a variety of tasks. This notion of generality underpins how Artificial General Intelligence (or AGI) is usually understood and the hopes and fears that accompany it.
But at least from the point of view of economic impacts, generality might be a red herring. For a task such as computational reproducibility on which expert humans collectively spend millions of hours every year, being able to automate it would be hugely impactful — regardless of whether the AI system did so out of the box, or after a few person days (or even a person year) of programmer effort.
In the AI Snake Oil book, we define generality as the inverse of task-specificity, and analyze how the history of AI (and computing) can be seen as the pursuit of gradually increasing generality. Increasing generality means decreasing the human effort it takes to build an AI system to perform a given task. From this perspective, systems like AutoGPT may be more general than most people (including us) gave them credit for.
Yet, definitions of AGI typically insist that a single system be able to do everything out of the box. There is no systematic effort to track how the human effort needed to build task-specific AI is changing over time. Just as we’ve argued against flawed conceptions of generality that overestimate AI progress, we should avoid flawed conceptions of generality that underestimate it.
Read the CORE-Bench paper here.
Further reading
In our recent paper, AI Agents That Matter, we found several shortcomings with AI agent evaluations. While building CORE-Bench, these shortcomings informed the design of our benchmark.
We recently organized an online workshop on useful and reliable AI agents where leading experts shared their views on better agent design and evaluation. The workshop videos are available online.
Ben Bogin et al. released the SUPER benchmark to evaluate if AI agents can set up and execute tasks from repositories accompanying research papers. It is another interesting benchmark for measuring AI agents' capability to automate research tasks. It differs from CORE-Bench in many ways:
CORE-Bench consists of tasks across scientific disciplines (computer science, medicine, social science) whereas SUPER consists of tasks from AI.
CORE-Bench requires the use of both vision-language and language models, and consists of multiple languages (Python and R) as opposed to SUPER (language models, Python).
Tasks in SUPER require access to a Jupyter notebook. In contrast, tasks in CORE-Bench require shell access and allow the agent to modify the sandbox arbitrarily.
Love it. Was just reviewing a paper in this area, I wish I could’ve pointed them to this.
Hopefully the benchmark is as hard as it looks! Long shelf life benchmarks are needed.
Outstanding contribution to the replicability crisis, thank you.