



New paper: AI agents that matter
Rethinking AI agent benchmarking and evaluation


Some of the most exciting applications of large language models involve taking real-world action, such as booking flight tickets or finding and fixing software bugs. AI systems that carry out such tasks are called agents. They use LLMs in combination with other software to use tools such as web search and code terminals.
The North Star of this field is to build assistants like Siri or Alexa and get them to actually work — handle complex tasks, accurately interpret users’ requests, and perform reliably. But this is far from a reality, and even the research direction is fairly new. To stimulate the development of agents and measure their effectiveness, researchers have created benchmark datasets. But as we’ve said before, LLM evaluation is a minefield, and it turns out that agent evaluation has a bunch of additional pitfalls that affect today’s benchmarks and evaluation practices. This state of affairs encourages the development of agents that do well on benchmarks without being useful in practice.
We have released a new paper that identifies the challenges in evaluating agents and proposes ways to address them. Read the paper here. The authors are Sayash Kapoor, Benedikt Ströbl, Zachary S. Siegel, Nitya Nadgir, and Arvind Narayanan, all at Princeton University.
In this post, we offer thoughts on the definition of AI agents, why we are cautiously optimistic about the future of AI agent research, whether AI agents are more hype or substance, and give a brief overview of the paper.
What does the term agent mean? Is it just a buzzword?
The term agent has been used by AI researchers without a formal definition.1 This has led to its being hijacked as a marketing term, and has generated a bit of pushback against its use. But the term isn’t meaningless. Many researchers have tried to formalize the community's intuitive understanding of what constitutes an agent in the context of language-model-based systems [1, 2, 3, 4, 5]. Rather than a binary, it can be seen as a spectrum, sometimes denoted by the term 'agentic'.
The five recent definitions of AI agents cited above are all distinct but with strong similarities to each other. Rather than propose a new definition, we identified three clusters of properties that cause an AI system to be considered more agentic according to existing definitions:
Environment and goals. The more complex the environment, the more AI systems operating in that environment are agentic. Complex environments are those that have a range of tasks and domains, multiple stakeholders, a long time horizon to take action, and unexpected changes. Further, systems that pursue complex goals without being instructed on how to pursue the goal are more agentic.
User interface and supervision. AI systems that can be instructed in natural language and act autonomously on the user's behalf are more agentic. In particular, systems that require less user supervision are more agentic. For example, chatbots cannot take real-world action, but adding plugins to chatbots (such as Zapier for ChatGPT) allows them to take some actions on behalf of users.
System design. Systems that use tools (like web search or code terminal) or planning (like reflecting on previous outputs or decomposing goals into subgoals) are more agentic. Systems whose control flow is driven by an LLM, rather than LLMs being invoked by a static program, are more agentic.
Do agents even work?
While some agents such as ChatGPT’s code interpreter / data analysis mode have been useful, more ambitious agent-based products so far have failed. The two main product launches based on AI agents have been the Rabbit R1 and Humane AI pin. These devices promised to eliminate or reduce phone dependence, but turned out to be too slow and unreliable. Devin, an “AI software engineer”, was announced with great hype 4 months ago, but has been panned in a video review and remains in waitlist-only mode. It is clear that if AI agents are to be useful in real-world products, they have a long way to go.
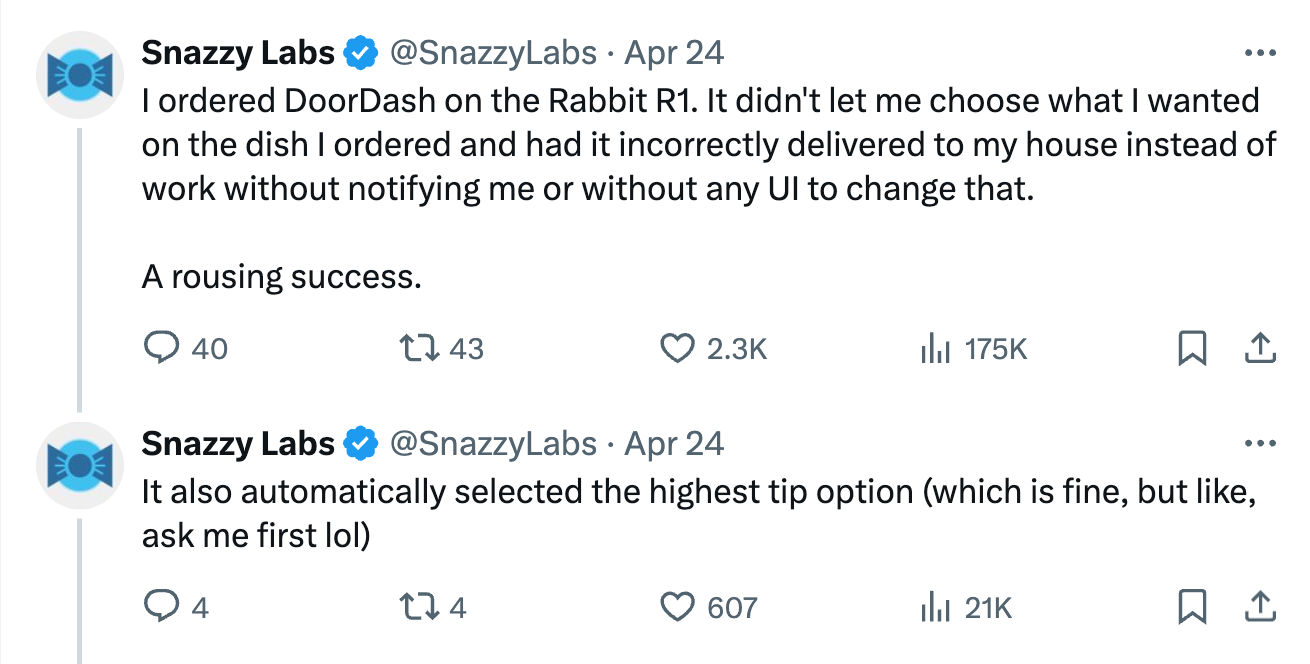
So are AI agents all hype? It’s too early to tell. We think there are research challenges to be solved before we can expect agents such as the ones above to work well enough to be widely adopted. The only way to find out is through more research, so we do think research on AI agents is worthwhile.
One major research challenge is reliability — LLMs are already capable enough to do many tasks that people want an assistant to handle, but not reliable enough that they can be successful products. To appreciate why, think of a flight-booking agent that needs to make dozens of calls to LLMs. If each of those went wrong independently with a probability of, say, just 2%, the overall system would be so unreliable as to be completely useless (this partly explains some of the product failures we’ve seen). So research on improving reliability might have many new applications even if the underlying language models don’t improve. And if scaling runs out, agents are the most natural direction for further progress in AI.
Right now, however, research is itself contributing to hype and overoptimism because evaluation practices are not rigorous enough, much like the early days of machine learning research before the common task method took hold. That brings us to our paper.
Contributions of the paper
What changes must the AI community implement to help stimulate the development of AI agents that are useful in the real world, and not just on benchmarks? This is the paper’s central question. We make five recommendations:
1. Implement cost-controlled evaluations. The language models underlying most AI agents are stochastic. This means simply calling the underlying model multiple times can increase accuracy. We show that such simple tricks can outperform complex agent architectures on the HumanEval benchmark, while costing much less. We argue that all agent evaluation must control for cost. (We originally published this finding here. In the two months since we published this post, Pareto curves and joint optimization of cost and accuracy have become increasingly common in agent evaluations.)
2. Jointly optimize accuracy and cost. Visualizing evaluation results as a Pareto curve of accuracy and inference cost opens up a new space of agent design: jointly optimizing the two metrics. We show how we can lower cost while maintaining accuracy on HotPotQA by implementing a modification to the DSPy framework.
3. Distinguish model and downstream benchmarking. Through a case study of NovelQA, we show how benchmarks meant for model evaluation can be misleading when used for downstream evaluation. We argue that downstream evaluation should account for dollar costs, rather than proxies for cost such as the number of model parameters.
4. Prevent shortcuts in agent benchmarks. We show that many types of overfitting to agent benchmarks are possible. We identify 4 levels of generality of agents and argue that different types of hold-out samples are needed based on the desired level of generality. Without proper hold-outs, agent developers can take shortcuts, even unintentionally. We illustrate this with a case study of the WebArena benchmark.
5. Improve the standardization and reproducibility of agent benchmarks. We found pervasive shortcomings in the reproducibility of WebArena and HumanEval evaluations. These errors inflate accuracy estimates and lead to overoptimism about agent capabilities.
Concluding thoughts: reasons for cautious optimism
AI agent benchmarking is new and best practices haven't yet been established, making it hard to distinguish genuine advances from hype. We think agents are sufficiently different from models that benchmarking practices need to be rethought. In our paper, we take the first steps toward a principled approach to agent benchmarking. We hope these steps will raise the rigor of AI agent evaluation and provide a firm foundation for progress.
A different strand of our research concerns the reproducibility crisis in ML-based research in scientific fields such as medicine or social science. At some level, our current paper is similar. In ML-based science, our outlook is that things will get worse before they get better. But in AI agents research, we are cautiously optimistic that practices will change quickly. One reason is that there is a stronger culture of sharing code and data alongside published papers, so errors are easier to spot. (This culture shift came about due to concerted efforts in the last five years.) Another reason is that overoptimistic research quickly gets a reality check when products based on misleading evaluations end up flopping. This is going to be an interesting space to watch over the next few years, both in terms of research and product releases.
In traditional AI, agents are defined entities that perceive and act upon their environment, but that definition is less useful in the LLM era — even a thermostat would qualify as an agent under that definition.
I took a slightly different approach and one from an enterprise automation practitioner perspective. Here is how Multi-Agent Framework, will help build the Autonomous Enterprise: https://www.linkedin.com/posts/doug-shannon_iot-iiot-edgecomputing-activity-7213534350049521665-mJ4j?utm_source=share&utm_medium=member_ios
The definition of "agents and agentic" needs to expand given the space that these are deployed in.
Even humans as agents cannot be useful or deployed in any space and do not have reliable general purpose evals.
Our general purpose evals are things like iq, reasoning but to have agency in a domain - we do not operate independently, we acquire specialized knowledge, we collaborate with humans and tools.
You can have practically useful agents specialized to domains that can operate well on domain specific evals rather than general purpose eval - think fine-tuning, tool knowhow, collaboration.
IMO before we jump down the evals well, we need to distinguish what we are evaluating for - practical outcomes or general reasoning.