



Scientists should use AI as a tool, not an oracle
How AI hype leads to flawed research that fuels more hype


Who produces AI hype? As we discuss in the AI Snake Oil book, it is not just companies and the media but also AI researchers. For example, a pair of widely-publicized papers in Nature in December 2023 claimed to have discovered over 2.2 million new materials using AI, and robotically synthesized 41 of them. Unfortunately, the claims were quickly debunked: “Most of the [41] materials produced were misidentified, and the rest were already known”. As for the large dataset, examining a sample of 250 compounds showed that it was mostly junk.
A core selling point of machine learning is discovery without understanding, which is why errors are particularly common in machine-learning-based science. Three years ago, we compiled evidence revealing that an error called leakage — the machine learning version of teaching to the test — was pervasive, affecting hundreds of papers from 17 disciplines. Since then, we have been trying to understand the problem better and devise solutions.
This post presents an update. In short, we think things will get worse before they get better, although there are glimmers of hope on the horizon.
The carnage continues
In our most recent compilation, the number of disciplines where researchers have uncovered leakage in published work has reached 30. The majority are medical fields, which we strongly suspect is due to the fact that since errors in medical research can be particularly consequential, medical fields seem to put much more effort into establishing best practices and critically reviewing previously published work. About 650 papers across all fields are affected, which we hypothesize is a vast underestimate — when researchers look for leakage systematically, in many fields they find that the majority of sampled studies commit the error of leakage.
Leakage is one of many reasons for reproducibility failures. There are widespread shortcomings in every step of ML-based science, from data collection to preprocessing and reporting results. Problems that might lead to irreproducibility include improper comparisons to baselines, unrepresentative samples, results being sensitive to specific modeling choices, and not reporting model uncertainties. There is also the basic problem of researchers failing to publish their code and data, precluding reproducibility. For example, Gabelica et al. examined 333 open-access journals indexed on BioMed Central in January 2019 and found that out of the 1,800 papers that pledged to share data upon request, 93% did not do so.
The roots run deep
Even before ML, many scientific fields have been facing reproducibility and replicability crises. The root causes include the publish-or-perish culture in science, the strong bias for publishing positive results (and the near-impossibility of publishing negative results), the lack of incentives for debunking faulty studies, and the lack of consequences for publishing shoddy work. For example, faulty papers are almost never retracted. Peers don’t even seem to notice replication failures — after a paper fails to replicate, only 3% of citing articles cited the replication attempt.1 Science communicators love to claim that science self-corrects, but self-correction is practically nonexistent in our experience.
All of these cultural factors are also present in ML-based science. But ML introduces a bunch of additional reasons why we should be skeptical of published results. Performance evaluation is notoriously tricky and many aspects of it, such as uncertainty quantification, are unresolved research areas. Also, ML code tends to vastly more complex and less standardized than traditional statistical modeling. Since it is not peer reviewers’ job to review code, coding errors are rarely discovered.
But we think the biggest reason for the poor quality of research is pervasive hype, resulting in the lack of a skeptical mindset among researchers, which is a cornerstone of good scientific practice. We’ve observed that when researchers have overoptimistic expectations, and their ML model performs poorly, they assume that they did something wrong and tweak the model, when in fact they should strongly consider the possibility that they have run up against inherent limits to predictability. Conversely, they tend to be credulous when their model performs well, when in fact they should be on high alert for leakage or other flaws. And if the model performs better than expected, they assume that it has discovered patterns in the data that no human could have thought of, and the myth of AI as an alien intelligence makes this explanation seem readily plausible.
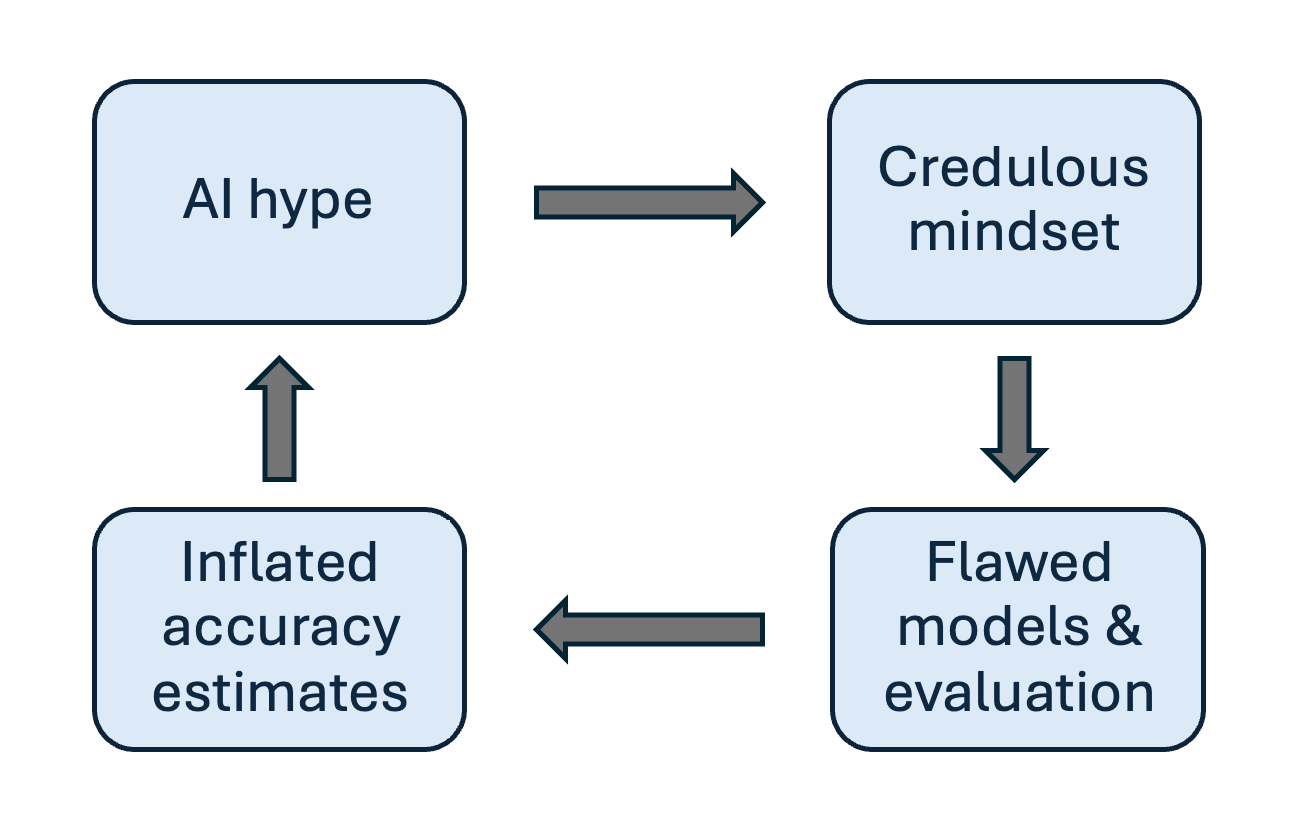
This is a feedback loop. Overoptimism fuels flawed research which further misleads other researchers in the field about what they should and shouldn’t expect AI to be able to do. In fact, we’ve encountered extreme versions of this in private correspondence with frustrated researchers: since flawed research goes uncorrected, it becomes literally impossible to publish good research since it will result in models that don’t beat the “state of the art”.
The more powerful and more black-box the tool, the more the potential for errors and overconfidence. The replication crises in psychology, medicine, etc. were the result of misapplication of plain old statistics. Given how relatively new ML is, our guess is that the reproducibility crisis in ML-based science will get worse for a while before it starts to get better. And now scientists are embracing large language models and generative AI, which open up many new pitfalls such as the illusion of understanding.
Glimmers of hope
One good thing about ML-based science is that it usually involves only data analysis, not experimenting on people. So other researchers should in principle be able to download a paper’s code and data and check whether they can reproduce the reported results. They can also review the code for any errors or problematic choices. This is time consuming, but much less so than replicating a study in psychology or medicine, which is typically almost as costly as the original study.
Another good thing is that the vast majority of errors can be avoided if the researchers know what to look out for. In contrast, mitigations for the replication crisis in statistical science, such as pre-registration, have a much more spotty track record of effectiveness.
So we think that the problem can be greatly mitigated by a culture change where researchers systematically exercise more care in their work and reproducibility studies are incentivized. The ML methods community has already moved in this direction via the common task method (which is decades old) and the reproducibility challenge (which is more recent), but this has not yet happened in ML-based science, that is, in disciplines like medicine or psychology that use ML models to advance knowledge in their respective fields.
We have led a few efforts to change this. First, our leakage paper has had an impact. It has been used by researchers to clarify how they build models and document and demonstrate the absence of leakage. It has been used by researchers trying to find leakage in published work. It has also been used as a way to underscore the importance of studying leakage and coming up with discipline-specific guidelines.
Beyond leakage, we led a group of 19 researchers across computer science, data science, social sciences, mathematics, and biomedical research to develop the REFORMS checklist for ML-based science. It is a 32-item checklist that can help researchers catch eight kinds of common pitfalls in ML-based science, of which leakage is only one. It was recently published in Science Advances. Of course, checklists by themselves won’t help if there isn’t a culture change, but based on the reception so far, we are cautiously optimistic.
Concluding thoughts
Our point isn’t that AI is useless to scientists. We ourselves frequently use AI as a tool, even in our research that’s not about AI. The key word is tool. AI is not a revolution. It is not a replacement for human understanding — to think so is to miss the point of science. AI does not offer a shortcut to the hard work and frustration inherent to research. AI is not an oracle and cannot see the future.
Unfortunately, most scientific fields have succumbed to AI hype, leading to a suspension of common sense. For example, a line of research in political science claimed to predict the onset of civil war with an accuracy2 of well over 90%, a number that should sound facially impossible. (It turned out to be leakage, which is what got us interested in this whole line of research.)
We are at an interesting moment in the history of science. Look at these graphs showing the adoption of AI in various fields:3

These hockey stick graphs are not good news. They should be terrifying. Adopting AI requires changes to scientific epistemology.4 No scientific field has the capacity to accomplish this on a timescale of a couple of years. This is not what happens when a tool or method is adopted organically. It happens when scientists jump on a trend to get funding. Given the level of hype, scientists don’t need additional incentives to adopt AI. That means AI-for-science funding programs are probably making things worse. We doubt the avalanche of flawed research can be stopped, but if at least a fraction of AI-for-science funding were diverted to better training, critical inquiry, meta-science, reproducibility, and other quality-control efforts, the havoc can be minimized.
Our book AI Snake Oil is now available to preorder. If you have enjoyed our blog and would like to support our work, please preorder via Amazon, Bookshop, or your favorite bookseller.
To be clear, replication failures don’t necessarily imply flaws in the original study. Our concern in this post is primarily about relatively clear-cut errors such as leakage.
Accuracy here refers to a metric called AUC; the baseline AUC is 50% even when one outcome (peace) is much more common than the other (war).
The paper clubs together different types of AI “engagement”: Engagement could include (but is not limited to) the development of novel AI theory and approaches, technologies, or applications; the general use of AI models for domain-specific tasks; and critical engagement with AI, as typified by academic discourse in fields like philosophy and ethics. This is unfortunate for our purposes, as our concern is solely about the second category, the use of AI for domain-specific tasks. We do think that outside of a few fields like computer science and philosophy, most AI engagement falls into this category.
In particular, as the saying goes, “all models are wrong but some models are useful”. There is no straightforward answer to the question of when we can draw conclusions about the world based on a model, so validity has to be re-litigated in every field and for every type of model.
“The end of the beginning” really was an apt description by Ben Thompson
Great read! The feedback loop of overoptimism fueling flawed research, further misleading or obfuscating fact finding is extremely worrisome.
It's a feedback loop that is maintained, and partly manufactured (if you want to get really cynical), by closed-source AI companies that benefit from over-attributing qualities to their newfound models and are happy to cheat benchmarks to beat the competition (on paper), as for them, it can be the difference between getting or not getting that next capital injection.